SGLang团队的博客:https://hebiao064.github.io/rl-memory-management
Overview
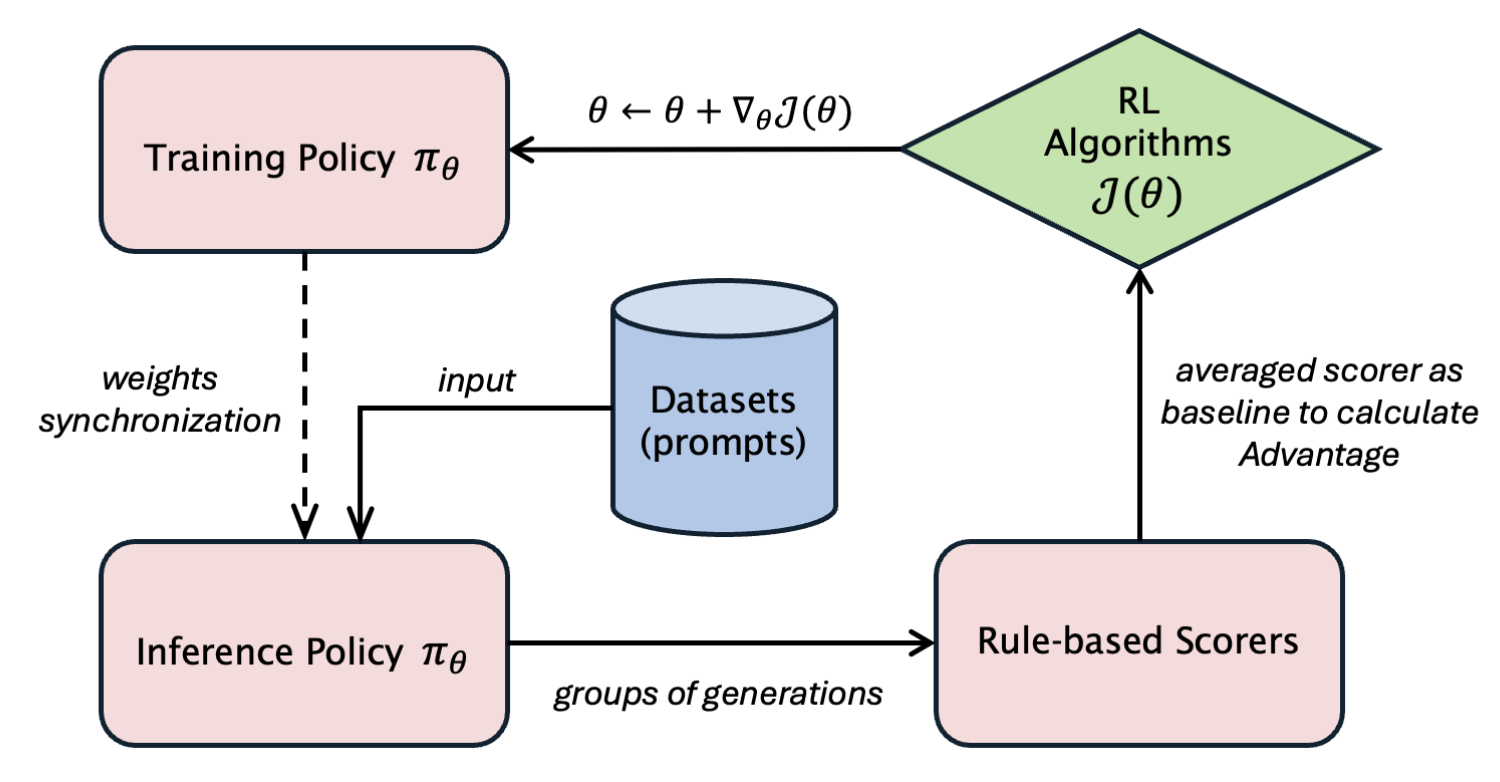
上述是简化的在线RL训练流程,隐去了reference和critic model,并且用基础的reward function而非reward model来说明流程。实际上就是policy model存在的training engine和rollout engine上需要进行优化。
从简化的PPO流程开始:
| |
每一个iter相当于是actor model进行一次rollout再进行training,而veRL因为rollout和training共部署,所以两边可能不用version的actor model是在相同的GPU组上的,这导致了虽然资源共享但是显存管理会变得更复杂。
显存问题
训练阶段显存
FSDP(fully sharded + full activation checkpointing)下,每个GPU占据显存: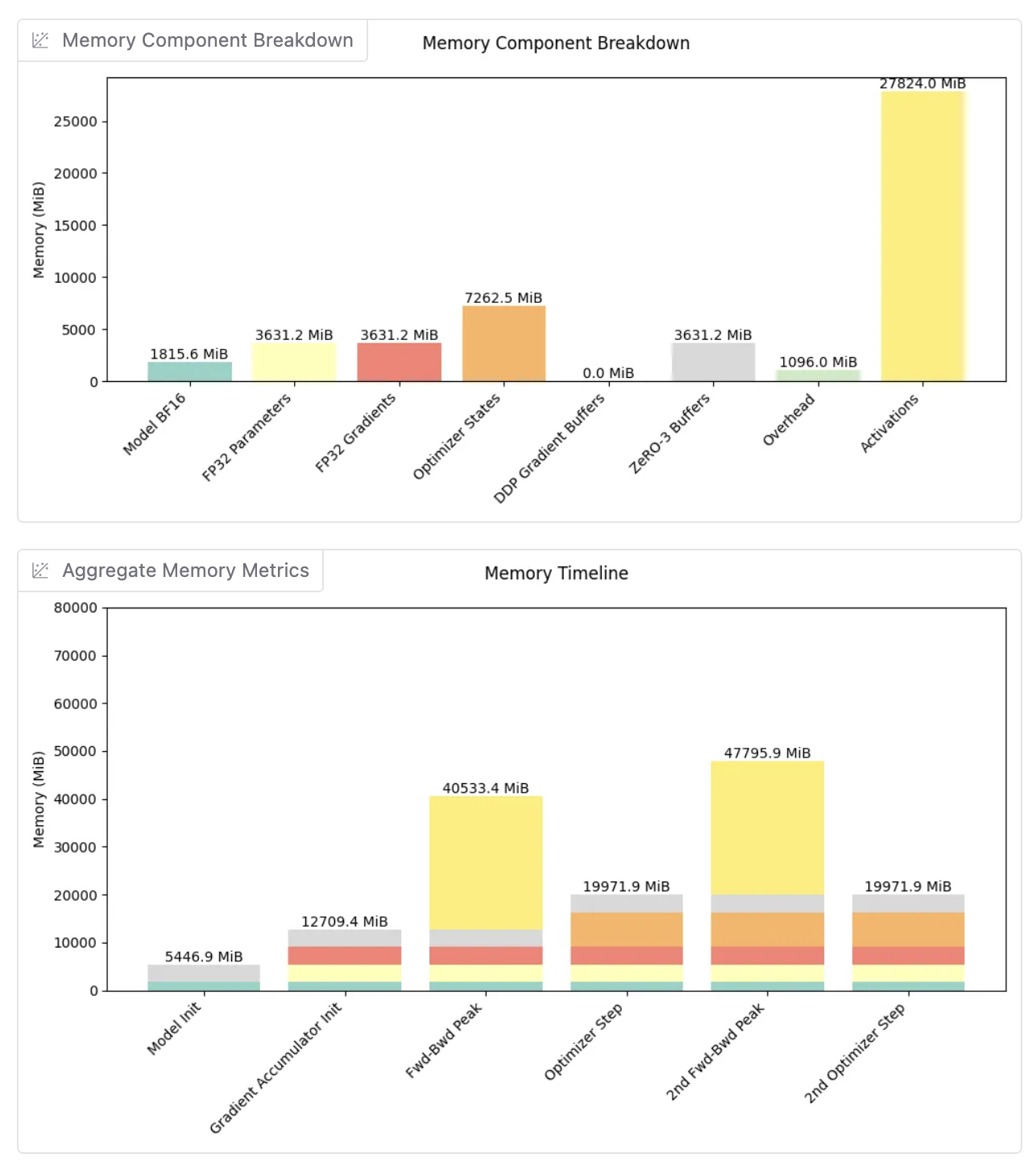
每个GPU的峰值显存:~48GB
推理阶段显存
During inference, the full model is typically loaded (not sharded):
- Model Weights: ~15.4 GB (full model for inference efficiency)
- KV Cache: ~60-90 GB (dominant factor, can be tuned by
mem-fractionin SGLang, assuming0.7-0.9ratio) - CUDA Graph: ~1-3 GB (captures computation graph for inference acceleration)
- Input/Output Buffers: ~3-7 GB (request batching and response generation)
Total Rollout Memory: ~80-115 GB per GPU
显存优化之路
offload weights to CPU after training
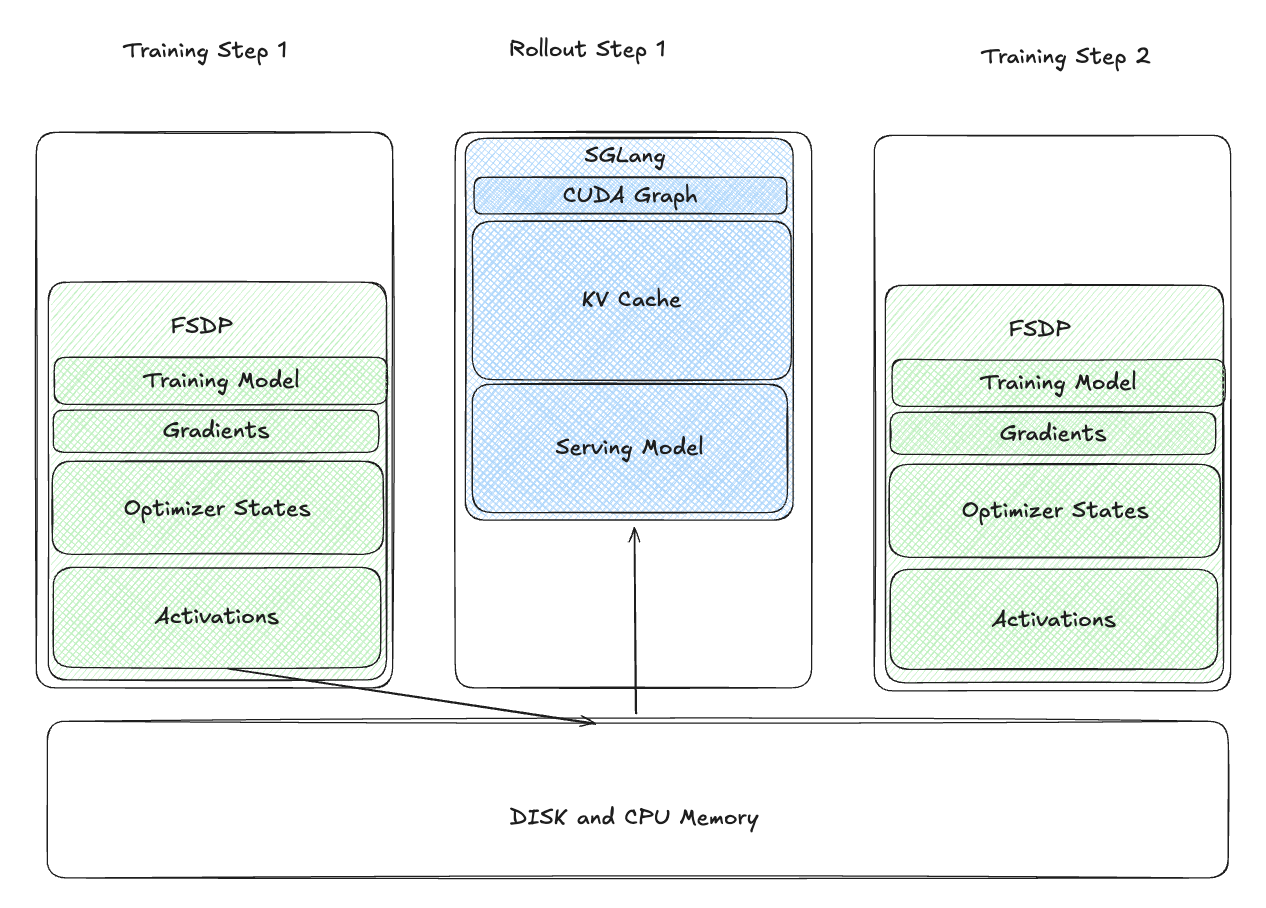
这种有两个显著的问题:
- Slow Disk I/O: 加载权重会变得非常耗时
- Recapture CUDA Graph:这也会带来额外的overhead
所以在实际场景里面性能太低了。
Sleeping the inference engine
SGLang团队探索在training阶段释放weights和kv cache memory的时候keep CUDA Graph alive。最主要的挑战是,当重建这些tensors的时候,因为虚拟内存地址的变化,导致CUDA Graph的reply会有问题。
因此,解决的问题可以被浓缩为:
- 在training的时候释放物理内存从而释放空间。
- 在rollout的时候,在相同的虚拟内存地址上,重新分配GPU显存给weights和kv cache。
SGLang因此开发了torch_memory_saver library,用于在保持CUDA Graph兼容性下,实现内存的释放(pause)和重建(resume)。
| |
使用CUDA Virtual Memory APIs实现
在CUDA 10.2之前,内存管理依赖于cudaMalloc、cudaFree以及cudaMemcpy,这些却并没有能力对虚拟内存地址进行管理。所以10.2开始,加了能够控制虚拟内存管理的API:
cuMemCreate: Creates a physical memory handle.cuMemAddressReserve: Reserves a virtual address range.cuMemMap: Maps a physical memory handle to a virtual address range.
基于这些API,可以做到自定义的memory allocator同时保留虚拟内存地址的能力。在SGLang和veRL系统中,使用LD_PRELOAD变量将自定义的allocator替换默认的cuda memory allocator。
修改后的CUDA Malloc
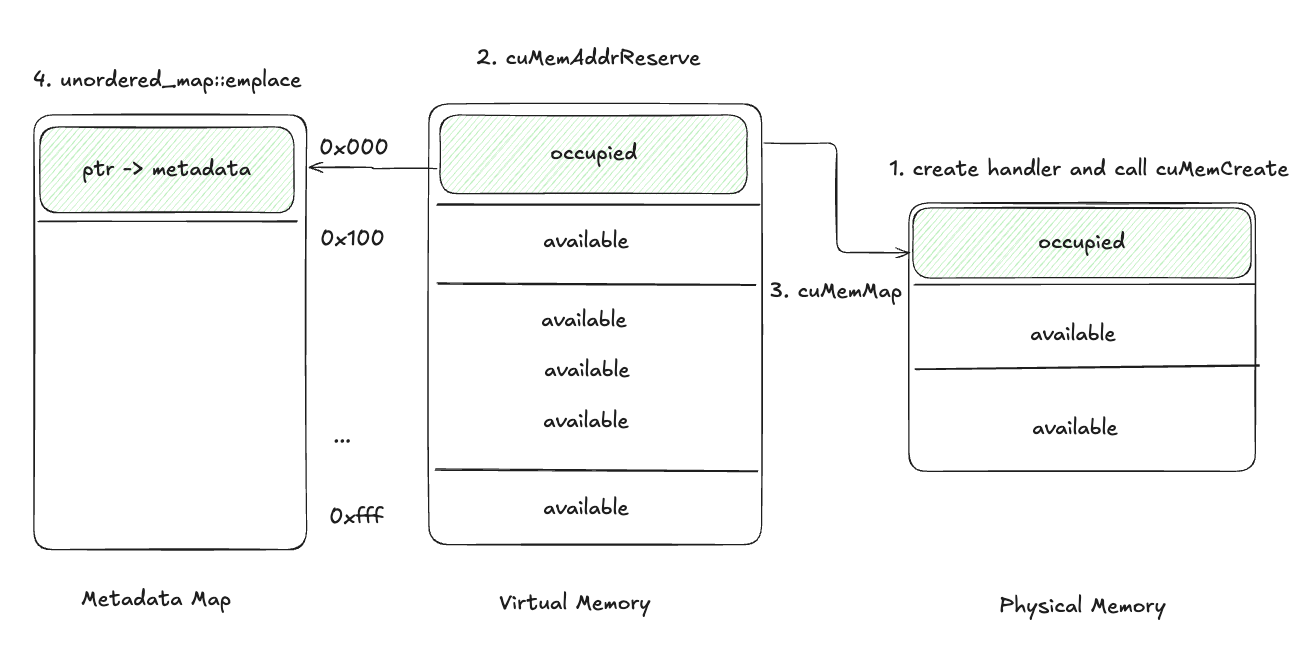
- 创建一个
CUmemGenericAllocationHandle且通过cuMemCreate分配物理内存。Handler携带了被分配的内存的必要信息,比如这些内存被分配的实际物理位置等等。 - 通过
cuMemAddressReserve对一段特定的虚拟内存地址进行保留。 - 通过
cuMemMap将物理地址和虚拟地址进行映射。 - 在Metadata Map中,存储虚拟内存pointer以及物理内存的handle。
释放tensors过程
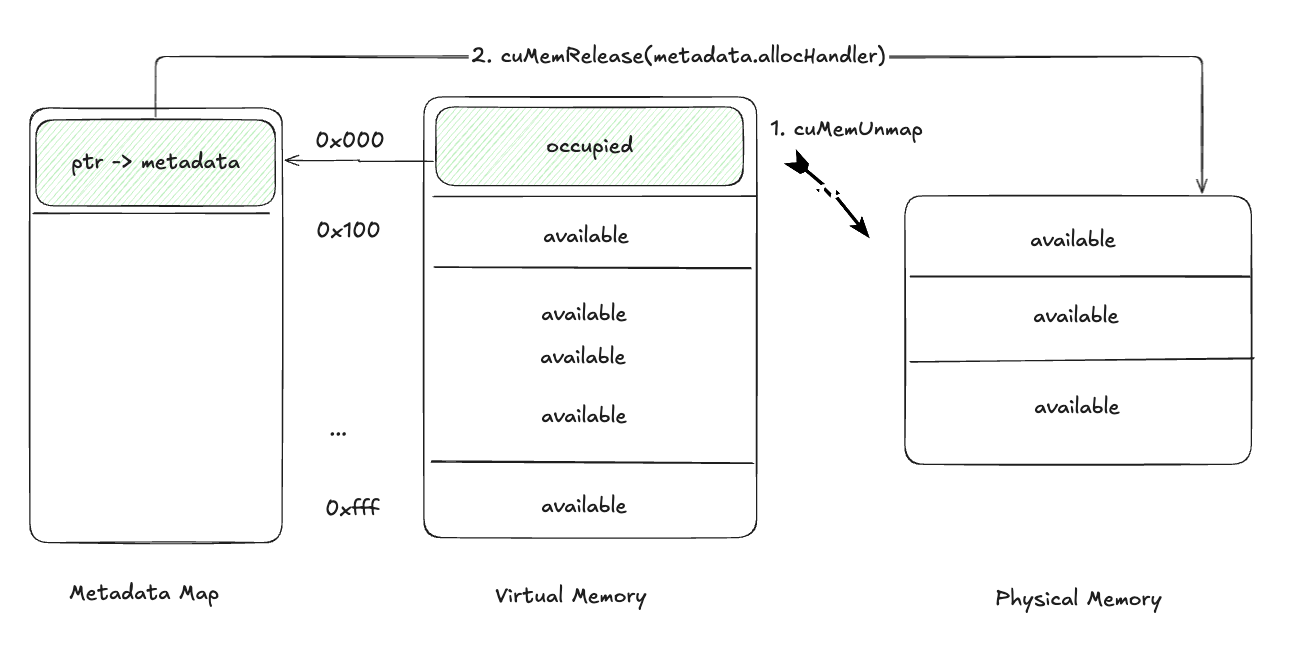
有了上面的基础,理解释放和重建的过程就很容易,先cuMemUnmap进行虚拟地址和物理地址的unmap,然后在Metadata Map中获取到真实的物理内存handle,通过cuMemRelease进行释放。
重建Tensors过程
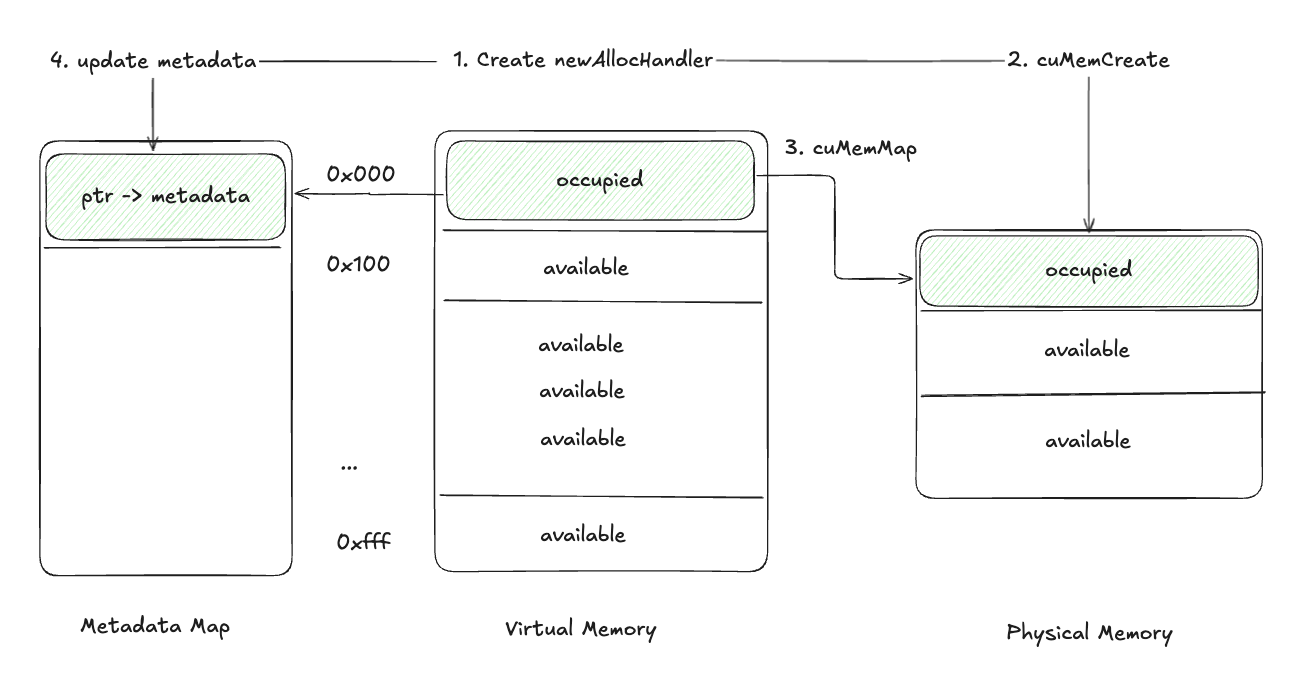
重建如一开始分析的那样,调用cuMemCreate新建handle,cuMemAlloc分配物理内存,通过cuMemMap再度将物理内存和已经存储的虚拟地址关联,最后把物理地址的handle存到Metadata Map里即可。
因此当前的solution可以被表示为: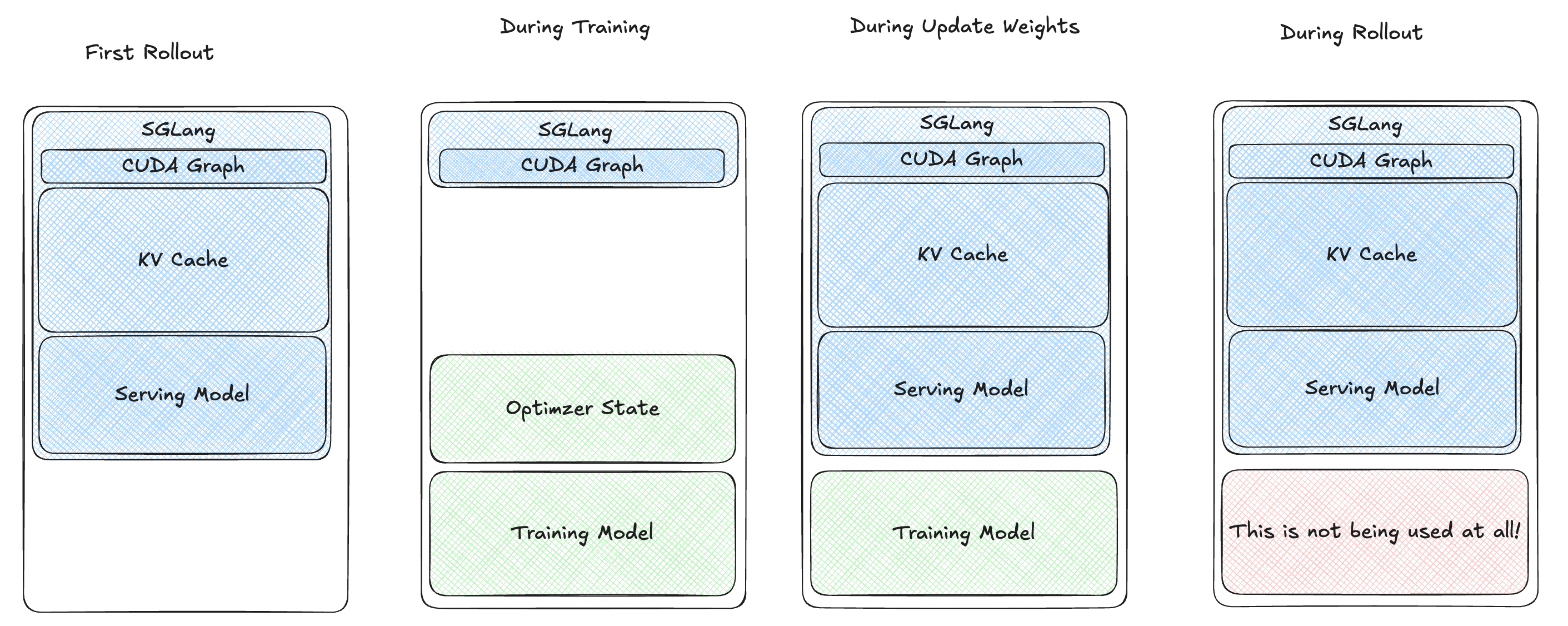
也就是不进行disk上的I/O进行weights加载,而是加载training model weights到GPU中,通过CUDA进程间通信,更新rollout engine的weights。这种training态到rollout态的转换的时间会大幅度降低,比如7B模型只有<0.5s。
Multi-Stage Awake
设计的RFC:https://github.com/sgl-project/sglang/issues/7009

上述的solution简单来说,分为几个阶段:
- training过程中,GPU上有training model以及optimizer state,training结束后,offload掉optimizer state 到CPU上并且保留model weights在GPU,进行权重更新。
- 权重更新时,唤醒SGLang engine,因此被paused的model weights和KV cache会被resume。而后使用sglang的
update_weights_in_tensor进行on-the-fly权重更新。 - 权重更新完了,在GPU中将training model删除。
上述的solution还有个问题,就是红框内的内存(被释放的training model)在rollout阶段是被浪费的,这会带来额外的问题:
- 较小的KV Cache: 因为KV Cache的Token数较少,需要使用相对小的mem fraction ratio (e.g: 0.6)。当KV Cache的Token数较少时,当我们要对大量的请求进行
prefill时,会出现报错:RuntimeError: Prefill out of memory. Try to lower your batch size. - OOM问题:当使用比如0.8的mem fraction ratio去在8卡H100上训练32B RL时,在更新权重的时候会OOM。
所以,为了解决这个问题,torch_memory_saver首先不能仅仅是singleton的,也就是SGLang在resume内存的时候,KV Cache和weights必须一起的场景需要拆解开。那么简单的思路有两个(RFC中均有提到):
torch_memory_saver做成多实例的,每个实例负责不同的stage。- 实现tag-based的pause/resume API。(维持原有的codebase下进行较小的改动)
SGLang团队采取第二种方案,还是基于singleton的设计。
Tag-Based Memory Management
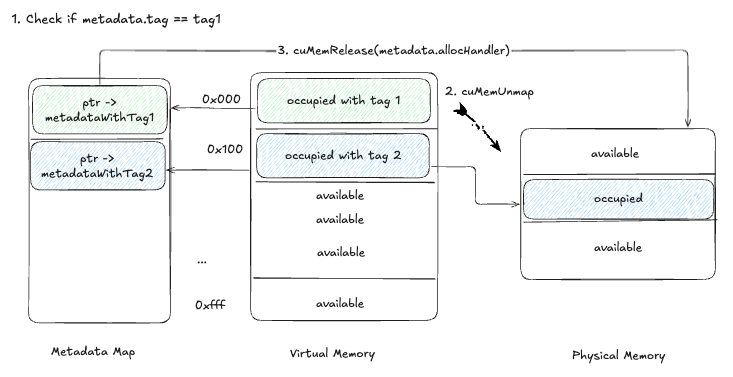
这个方案比较直观,也就是在tensor metadata里区分Tag,从而使能selective pausing/resuming。
新的pause过程为:
- 针对每个tensor的metadata进行tag matching。
- 如果matched, 用
cuMemUnmap进行unmap操作。 - 通过
cuMemRelease进行物理内存的释放。
新的API如下:
| |
因此multi-stage的resume过程可以表示为:
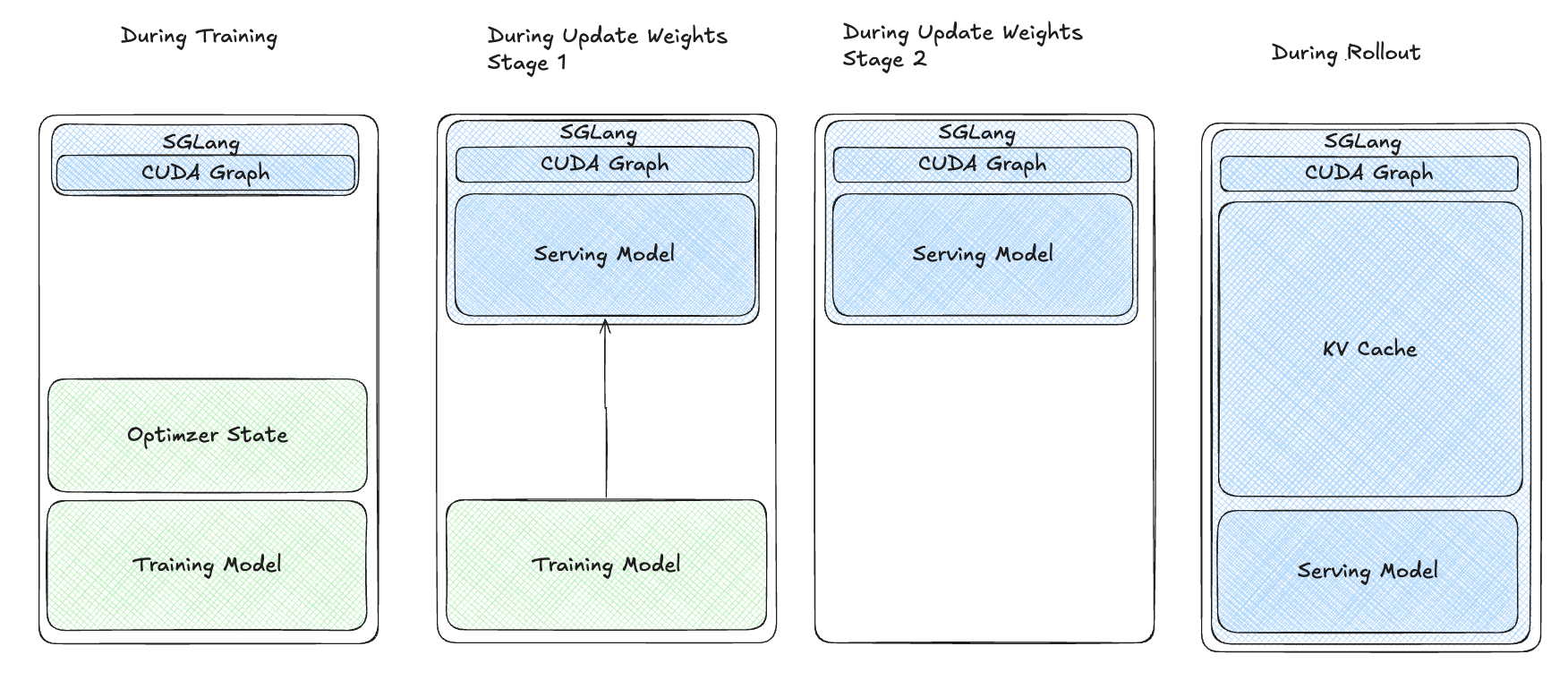
这种方案可以最小化内存的浪费,解决OOM的问题,并且在较大的kv cache ratio或者较大模型上都能提升效率。
总结
基于上述的优化,实现了在8卡H100进行Qwen-32B基于0.9 KV Cache memory ratio的RL训练。