理解LLM推理中deterministic问题来源
Wiki上对deterministic算法的定义是:
“a deterministic algorithm is an algorithm that, given a particular input, will always produce the same output.”
而我们在文中要讨论的,即对于LLM这个context下的deterministic问题,我会先从inference角度(即重复给定一个确定的input,模型的推理为什么无法给定确定的输出)进行问题的理解,再进一步讨论RL工程中的training & inference之间差异,可能会导致RL训练的崩溃问题,并继续讨论业界现在已有的解决方案、与还在working-in-progress的工作。
浮点数的非结合性
thinking machines lab针对batch invariant讨论的文章,详细地解释了在LLM推理中不确定性的来原,即因为精度有限,GPU浮点数运算中的结合性通常不成立:
$$(a+b)+c \neq a+(b+c) $$
这篇arxiv文章,则更深入得说明了这个问题:
Floating-point arithmetic in GPUs exhibits non-associativity, meaning (a+b)+c≠a+(b+c) due to finite precision and rounding errors. This property directly impacts the computation of attention scores and logits in the transformer architecture, where parallel operations across multiple threads can yield different results based on execution order.
浮点数通常可用科学计数的表示来表征大/小数,例如格式$mantissa *10^{exponent}$,如果指数项是不同的,也就是文中说的add at different scales,那不同累加序导致的精度损失会更加明显,而这种不同scale的累加是最常见的场景。
但是尽管这是不一致输出的根本原因,但是并没有回答不确定性源自何处。无法帮助我们去理解:浮点数值为何会以不同的顺序相加、这种情况何时会发生,已经如何避免这种情况。
为何计算内核不同序add numbers?
一个常见的假说是“并发执行随机性 + 浮点运算误差”。这个假说的核心观点,就是如果并发线程的结束顺序是非确定的,并且数值累加顺序如果依赖于并发线程的结束顺序(例如使用atomic add操作),那么最终数值累加的顺序也是非确定的。
什么时候真正需要atomic add?
但是问题是,LLM前向的GPU内核实际上很少用atomic add操作。
简单解释下Atomic Add的含义:GPU 会把同一段程序同时扔到很多“小核”(SM)上去跑。这些小核之间天生没有步调一致的机制,谁快谁慢完全看当时心情。于是,如果它们需要把结果写到同一个地方,就会出问题。那atomic add就是,硬件保证所有人的结果最终都会加进去,但谁先谁后、按什么顺序加,完全不保证,因此每次跑出来的累加顺序都可能不一样。
再举个例子,通过torch.sum()对100个数求和,GPU 可以让 100 个小核各读一个数,这一步完全并行。可最后总得把 100 个数合并成 1 个总和。若用原子加,就是让每个小核随便谁先到,就先把它的数塞到同一个累加器里。硬件只负责“不会丢数”,却不负责“按固定顺序加”。于是同样跑两遍,先加谁后加谁可能不同,结果也就可能出现那一点点浮点误差。
我们回想通常定义的不确定性的含义:同一段 kernel、同一批输入,跑两遍却得到两个略有差异的结果。这叫“run-to-run 非确定性”——哪怕 Python 脚本、依赖库、硬件都没变,第二次跑就是能给你不一样的数。虽然atomic add会导致这个问题,但是更通常的情况是,LLM一次典型的forward,通常一个atomic add也没有。
这主要有两个原因:
- batch维度上实际上已经“人多势众”,根本不需要在reduction维度再去并行。
- 大多数neural networking library也用了很多技巧来实现“既保障确定性又快”,例如“分段树形归约”(split/tree reduction),可以先把100个数拆成5组,每组20个数,5个小核并行计算一个局部和。剩下 5 个局部和要么交给一个核顺序“扫尾”(元素少,开销可忽略),要么用信号量(semaphore)按固定顺序让不同线程块依次累加,从而保证先后顺序一致,结果也就 deterministic 了。
不过,在pytorch中的scatter_add操作(a[b] += c),如果不用atomic add性能会特别慢,而LLM中唯一踩这个坑的,是FlashAttention的反向传播。
不过当前Triton版本FA反向实现,其实和Tri Dao原论文里的算法不完全一样,Triton版为了躲开atomic add,额外多算了一遍中间结果–FLOPS直接多了40%,但是换来了determinstic,也算明码标价。
但是正向传播里,LLM中根本就没有非得用atomic add的算子,所以结论就是:LLM 的前向推理,跑两次、跑一百次,结果比特级完全一致;真正可能“每次不一样”的,只出在反向训练阶段,而且基本就 FlashAttention 一家。(也就是前向是“run-to-run deterministic”的)。
系统级别批次不变性的缺失(batch invariant)
前向kernel函数的确定性,实际上不等于整个推理服务对外表现确定,也就是还存在额外的系统级非确定性。因为真正喂给前向的张量内容还可能被其他“外部输入”左右,比如batch_size,也就是仍缺失“批次不变性”(batch invariance):同一请求、同一模型权重,只要推理时动态批大小不同,可能会导致tilesize不同,导致reduce的计算结果不同。
更细节去深究,比如Attention计算时,当kvcache很长的时候,就需要沿着KV维度进行分割:
- split reduction kernels: Split-KV或者FlashDecoding。
- 根据batch size动态选择分割数量,会导致不同的reduction顺序。
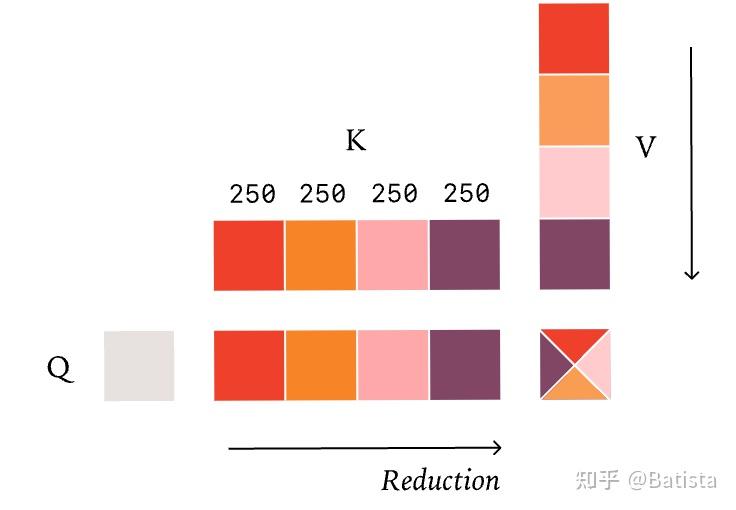
若不沿着规约维度进行并行,那么只能在batch、head、query维度进行并行,在decoding阶段,query本身就短,除非是大batch,那么gpu的计算内核很多会空转。
再者,内存的访问模式可能也随着batch size的大小而变化,可能导致不同的stride:
| |
batch size数值的变化不会必然导致stride变化,stride变化主要原因是张量布局改变,而布局常常因为batch size不同而被program主动
.view/.transpose等操作修改。
M/N不同(行/列长度不同),可能会引入不同的内存对齐,compiler可能会选不同的tile/block/warp划分或者加pad,间接导致不同的微观计算执行顺序。
| |
所以针对推理引擎,比如要在kernel层面实现batch invariant才能真正解决serve层面不确定性的问题。
和并行策略相关的Reduction不确定性
TODO: 通信库的通信算子带来的规约不确定性。
export HCCL_DETERMINISTIC=true
开启HCCL的规约类算子的确定性计算。
Batch Invariant的相关工作
batch invariant ops
Thinking Machines Lab发布了batch invariant的部分kernel算子实现。
而从原blog里,提出了三种难度递增的实现。
batch invariant的RMSNorm
直接让每个Batch元素的reduction顺序固定,不受batch大小影响。
- batch大时,把单个batch元素分配给单个核心,reduction运算在单核心内完成,batch增大时让核心依次处理多个元素,保持reduction策略不变。
- batch小时,若采用"split reduction"(多核心分担reduction以提升并行度)会破坏batch invariant,可以选择忽略小batch优化(小batch本身执行就快,性能损失可以接受),或者采用固定reduction策略(牺牲部分性能来保证batch invariant)。
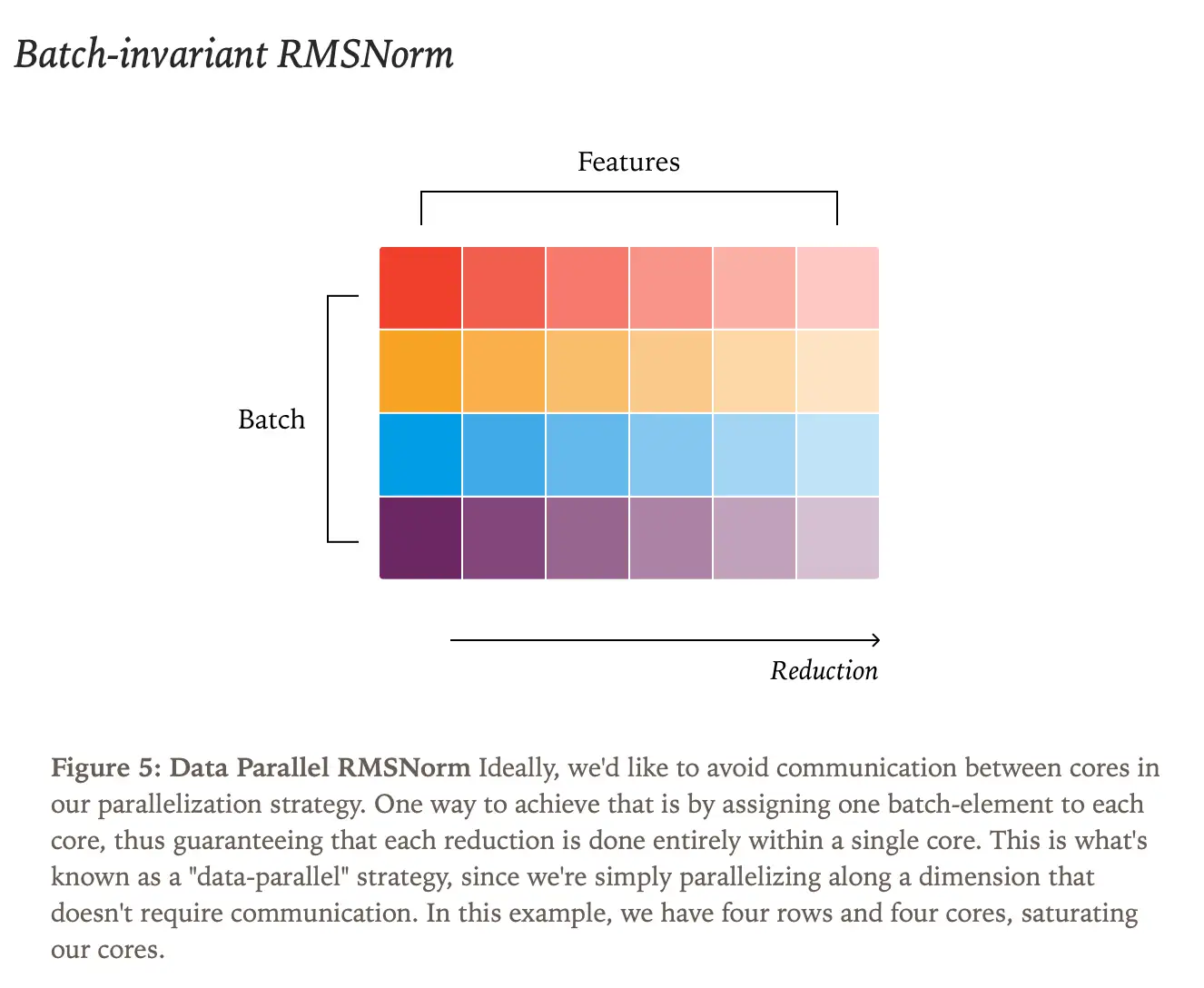
batch invariant的矩阵乘法
将输出张量拆分为2D tiles,每个tile分配给单个核心,reduction在单个核心内部完成。编译固定配置的内核以适配所有形状,虽然会损失20%性能(和cuBLAS相比),但在LLM推理中通常可以接受,因为模型维度(N)比较大,对split-k的需求较低。
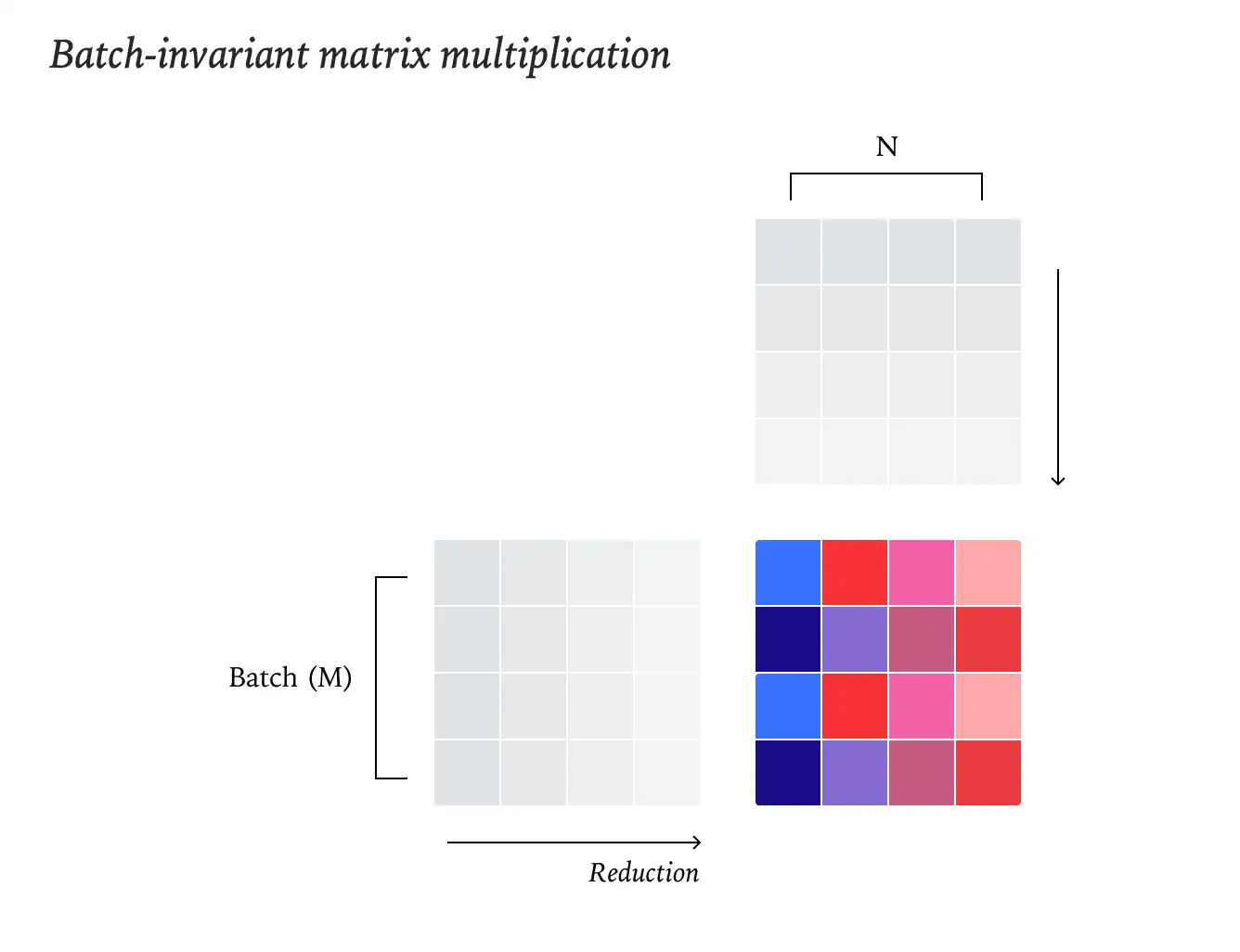
batch invariant的注意力计算
采用data-parallel策略(沿着Q张量并行,reduction在单核心内完成),更新KV缓存和页表以保证KV布局一致,不受处理token数量的影响。
decode阶段Q长度小,需要拆分KV维度(Split-KV),采用固定拆分大小策略(而非固定拆分数量),确保reduction顺序不变,比如把1000长度的KV拆成3个256长度和1个232长度的片段,而不是4个250长度的片段。
传统 batch 变化(来 1 条还是 32 条)会让 reduce 并行度变化 → 累加序变化。
这里把「并行」只放到 无 reduce 的 Q 维(data-parallel),而把 带 reduce 的 KV 维用 固定 tile 大小串行扫完。
于是 batch 数只影响开多少核,不影响 reduce 顺序,实现「batch 变化,结果不变」的 deterministic attention。
Sglang / vLLM 实现deterministic inference
SGLang团队的博客里记录了实现的细节,主要是针对batch invariant kernel上,针对chunked prefill、cuda graph等特性做了兼容,具体可以参考RoadMap。
vLLM参考Enabling Batch Invariant文档,也可以参考RFC #28326,#27433。
On-policy RL训练中的训推不一致问题
训推不一致问题,在RL训练上实际上是不可忽视的,主要由于训练侧(FSDP、Megatron等)和推理侧(vllm、sglang、trt等)这类kernel差异、计算实现路径差异、硬件侧针对两边不同优化这类问题导致的系统性偏差。而且这类偏差,在数学上可能会导致:
Bias: 训练优化器会主动走向一个错误的结果。Variance:优化器会完全停滞,让训练中止。
在后面算法的章节,在理论上也会对不一致问题对RL影响进行数学上的分析。
有研究指出 train / inference engine之间的不一致会隐性导致on-policy假设的RL实际变成off-policy。所以当我们追求"真正的" on-policy RL训练时,需要知道:
如果不能从两个完全一致的推理请求中获取bitwise相等的结果,那么当然也无法保障训推之间的bitwise一致性。所以基于之前我们对确定性推理实现讨论,直觉上可以知道如果保证了确定性推理,那么通过修改训练这部分stack,也能够实现在bitwise上训推的一致性,从而实现真正的on-policy RL训练。
而业界对这个问题的解决思路上主要分为两种:
在训练引擎侧,基于推理引擎(vllm/sglang)确定性推理内核前向实现,进行反向传递的实现,通过对齐kernel的实现,做到训练和采样部分的bitwise一致性(i.e. 0 KL divergence)。
拥抱训推分布的不一致(考虑到训练bitwise实现在工程上的工作量,和不同模型适配的工作量),在算法上为off-policy做off-policy correction,进行训推KL散度的偏差抑制,在大多数场景也能实现RL训练的平滑和目标效果。
后续会分别着重分析这两种解决思路。
不一致问题分析
这篇文章 从实验的角度来对rollout-training不一致问题进行了分析,主要得出的结论是,不同的并行策略以及更长的响应长度会增大二者之间的mismatch,而选择不同的推理后端的影响比较小。




这些消融实验可以带来一些经验的归纳,也就是说明现象。但是笔者认为并不能让我们完全理解mismatch产生的原因。笔者认为,不一致性的主要来源,还是因为训练(FSDP、Megatron等)和推理(vLLM、SGLang等)是针对不同计算pattern进行了各自侧重的优化,不论是前向的kernel算子差异带来的数值精度误差累积,还是切分策略带来的通信算子规约顺序带来的精度误差累计,都是mismatch的原因一部分。
而像MoE模型的稀疏以及动态路由特性,会带来比Dense模型更大的mismatch,因为路由机制本身就是数值精度敏感的,一些微小的数值差异,会带来差异巨大的专家激活。除此之外,MoE模型本身的稀疏特性,和Dense模型相比一般规模会更大,而现代的推理引擎,通常针对MoE模型有独特的优化手段(计算、通信),也会放大训推引擎之间的不一致性。
而字节团队的这篇文章,对训推不一致问题进行了更加深入的理论、实验分析,针对不一致的现象,也提出了更genearal的叙述:
To achieve the massive throughput required, modern inference engines (e.g., vLLM, SGLang, TensorRT-LLM) employ aggressive optimization strategies like speculative decoding, low-precision computation (INT8/FP8), and specialized, batch-variant CUDA kernels. While maintaining sampling fidelity, the primary objective of modern inference engines is to maximize throughput, often measured in tokens per second. Conversely, training frameworks (e.g., FSDP, DeepSpeed, Megatron-LM) must strike a different balance, prioritizing numerical stability and precision for gradient computation, often using higher-precision formats like FP32 for master weights and optimizer states. This divergence in optimization priorities and constraints creates an inevitable training-inference mismatch.
因此,我们可以回到一开始提到的业界解决on-policy RL训推不一致问题的两个思路,实际上是在性能和一致性上trade-off的取舍,如果希望对齐训推计算(例如之前讨论的batch invariant),势必会带来性能上的劣化。
从这篇文档,能得到很多有用的takeaways,比如实验中衡量不一致性的用的是下面的vllm-klmetric:
这个metric的异常spike,通常能导致训练侧entropy和rewards的异常波动。
而vllm-kl的spike同时会导致fsdp-ppl和gradient norm的爆炸性波动,这表示FSDP engine给推理引擎采样的得到的tokens设置特别小的概率,导致梯度爆炸,从而让RL训练崩溃。
以及mismatch不是均匀分布的,如果推理引擎得到的token概率越接近0,那在训练侧这个token的概率会更严重地被压小,让mismatch更大。

除此之外,还发现OOD tools的返回比如multi-turn TIR会带来更大的mismatch等等问题。
所以综上所述,在当前的RL框架中,训推引擎之间的不一致,是一个不可避免的问题,如果不一致问题非常严重,容易导致训练崩溃这样的严重后果(特别在长稳训练下)。
接下来笔者详细介绍一下,业界针对不一致问题的解决思路和方案。
硬对齐训推前反向不同kernel
TorchTitan + vLLM
TorchTitan项目探索了基于vllm的确定性RL的实现,基于vllm的确定性前向实现,补充了vllm operations的反向传播。其具体的实现为:
- 利用vLLM的
batch invariant前向实现。
| |
- 实现了自定义的反向函数进行梯度计算。
| |
- 提供了torchtitan和vllm侧不同格式的权重转换能力。
Slime + SGLang
SGLang团队在Thinking Machines Lab发布的批次不变算子基础之上,通过定制一系列注意力算子和采样逻辑,也实现了完全确定性推理。该实现同时保持与分块预填充 (chunked prefill)、CUDA Graph、Radix Cache 和非贪婪采样 (non-greedy sampling) 等关键功能的兼容性。SGLang侧的主要增强工作为:
- 集成Thinking Machines Lab的批次不变(batch invariant)算子。
- 实现固定KV分割大小的批次不变注意力算子。支持多种后端,包括 FlashInfer、FlashAttention 3和Triton。
- 与关键推理性能相关功能完全兼容,例如分块预填充、CUDA图、基数缓存等,当启用确定性推理时,所有这些功能都仍受支持。
- 支持按请求设置采样种子(per-request sampling seed),即使在temperature>0的非贪婪采样模式下也能实现确定性推理。
而在slime侧,主要是进行了torch设置:
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.use_deterministic_algorithms(True, warn_only=False)
以及环境变量:
- setting environment variable
NCCL_ALGO=Ring,NVTE_ALLOW_NONDETERMINISTIC_ALGO=0,CUBLAS_WORKSPACE_CONFIG=:4096:8; - 针对megatron后端设置
--deterministic-mode
详细可以看此PR。
RL算法侧缓解差异(off-policy correction)
数学直觉和分析工具
首先我们需要在数学上对mismatch问题给训练带来影响建立一些理论直觉,针对后续的一些算法工作,才会知道为什么这些是work的,哪些是可能还是有问题的。
这篇工作在数学上分析了RL break的原因。首先基于stochastic gradient ascent lemma建立了分析的约束工具:$\mathbb{E}[J(\theta_{k+1})] - J(\theta_k),$而这个式子被下面的表示约束:
$$\mathbb{E}[J(\theta_{k+1})] - J(\theta_k) \geq \text{Term A} + \text{Term B} - \text{Term C}$$
其中:
- Term A (True Progress): $\eta (1 - \frac{L\eta}{2})|\nabla J|^2$
- 对于真实的、无噪声的梯度的训练progess。
- Term B (Bias Error): $\eta(1 - L\eta)\langle \nabla J, \mathbf{Bias}(\hat{g}) \rangle$
- 计算系统级别异常导致的偏差。
- Term C (Noise Error): $\frac{L\eta^2}{2}[\mathbf{Var}(\hat{g}) + |\mathbf{Bias}(\hat{g})|^2]$
- 对于噪声和bias幅度的penalty。
基于上面的式子,有几个takeways:
- $\mathbf{Bias}(\hat{g}) = \mathbb{E}[\hat{g}] - \nabla J$ 这个差异衡量了estimator的systematic error,而在Term B中,$\langle \nabla J, \mathbf{Bias} \rangle$ 衡量了真实梯度和这个error关系。可以看到,如果bias比较小,或者是随机的,这个式子接近0,everything is fine。但是如果bias是系统级别的,并且和真实梯度有显著差异,那么点积会变得很大。一个负的Term B,代表着optimizer自己和自己“打架”,这不仅仅是训练变慢,而是逐渐和最优点逐渐偏离。因此,高的bias会导致一个错误的优化结果。
- $\mathbf{Var}(\hat{g}) = \mathbb{E}[|\hat{g}|^2] - |\mathbb{E}[\hat{g}]|^2$ 方差衡量了estimator的noise,这个noise error总是负数,并且scales with $\eta^2$,作为上面式子里的penalty。所以如果var比较高,这个负值会变大,那么为了保证优化的稳定(i.e. 确保Term A > Term C),我们只能被迫使用一个更小的学习率$\eta$ 。而且随着优化的进行,$\eta$也必须scale with $O(1/\mathbf{Var}).$。所以高方差 => 低学习率 => 缓慢的优化进展,所以训练的loss没崩掉,不是因为问题解决了,而是优化器本身就慢的很。
所以,算法侧的目标,应该是既要控制bias也要控制variance。
衡量bias和variance分别用下面两种工具:
- Total Variation (TV) Distance : $$D_{TV}(\mu \| \pi) = \frac{1}{2}\sum_y |\mu(y) - \pi(y)|$$
这个公式用来衡量bias,用来量化Term B的影响。 - Chi-Square ($\chi^2$) Distance: $$\chi^2(\pi\|\mu) = \mathbb{E}_\mu\left[\left(\frac{\pi(y)}{\mu(y)}\right)^2\right] - 1 = \mathbb{E}_\mu[\rho^2] - 1$$ 公式由IS(重要性采样)的二阶矩定义,用于衡量重要性采样 estimator的variance,$\mathbb{E}_\mu[\rho^2].$。如果这个值很大或者到inf,说明variance已经无法控制了,这个式子用来衡量Term C的影响。
Mismatch Importance Sampling
TIS(截断重要性采样)
比较早的博客是(Yao et al.2025),分析了用重要性采样从算法上缓解训推不一致性的问题。对REINFORCE的梯度表示:
$$\mathbb{E}_{a \sim \textcolor{red}{\pi_{\text{sampler}}}(\theta)} [R(a)\cdot \nabla_\theta \log \textcolor{blue}{\pi_{\text{learner}}}(a, \theta)],$$转换为:
$$\mathbb{E}_{a \sim \textcolor{red}{\pi_{\text{sampler}}}(\theta)} \Bigl[\frac{\textcolor{blue}{\pi_{\text{learner}}}(a, \theta)}{\textcolor{red}{\pi_{\text{sampler}}}(a, \theta)} \cdot R(a)\cdot \nabla_\theta \log \textcolor{blue}{\pi_{\text{learner}}}(a, \theta)\Bigr].$$
而后基于比较经典的TIS方法,可以实现更稳定的重要性采样:
扩展到PPO算法,策略梯度为经典的公式:
$$\small{ \mathbb{E}_{a\sim\pi_{\theta_{\mathrm{old}}}} \Bigl[ \nabla_\theta \min\Bigl( \frac{\pi_\theta(a)}{\pi_{\theta_{\mathrm{old}}}(a)}\,\hat A, \;\mathrm{clip}\bigl(\frac{\pi_\theta(a)}{\pi_{\theta_{\mathrm{old}}}(a)},\,1-\epsilon,\,1+\epsilon\bigr)\,\hat A \Bigr) \Bigr]}.$$
为了提升吞吐,Hybrid RL系统比如veRL使用vLLM这类推理引擎做rollout采样,而后回到训练侧用训练引擎再做一次 $\pi_{\theta old}$的recompute:
同样的,这种训练和推理的mismatch会出现,那么可以使用TIS进行校准:
文中也做了一些对比实验,表示此类校准确实能减少训推之间的计算分布差异:
除此之外,不同的IS变种的效果也有所不同。例如Colossal框架使用的PPO-IS格式:
$$\small{ \mathbb{E}_{a\sim\textcolor{red}{\pi_{\mathrm{sampler}}}(\theta_{\mathrm{old}})}\Bigl[\nabla_{\theta}\,\min\Bigl( \frac{\textcolor{blue}{\pi_{\mathrm{learner}}}(a,\;\theta)}{\textcolor{red}{\pi_{\mathrm{sampler}}}(a,\;\theta_{\mathrm{old}})}\,\hat{A}, \mathrm{clip}\Bigl( \frac{\textcolor{blue}{\pi_{\mathrm{learner}}}(a,\;\theta)}{\textcolor{red}{\pi_{\mathrm{sampler}}}(a,\;\theta_{\mathrm{old}})}, 1-\epsilon,\;1+\epsilon \Bigr)\,\hat{A}\Bigr)\Bigr]}$$
以及Nemo-RL框架使用的格式:
对比下来还是TIS更加稳定,特别是在训推不同量化这种场景下(e.g. FP8/INT8),更加明显。
更多的IS变种
更进一步的,前面介绍的字节的这篇工作还是更细致分析了不同IS:
Token-level / Sequence-level TIS
- 给定upper和lower bound,针对weights超过这个部分的做clip。
Token-level / Sequence-level MIS
- 给定upper和lower bound,将超出这个范围的weights置为0,相当与mask out掉,这个策略更加激进,适合处理极端的mismatch
简单来说,有以下的几个结论。
- 给定upper和lower bound,将超出这个范围的weights置为0,相当与mask out掉,这个策略更加激进,适合处理极端的mismatch
Token-level的IS是理论有偏(biased)的估计,而Sequence-level的IS是无偏的估计,通常能有更稳定的训练。

在复杂的场景(例如TIR),token-level的TIS还是会failed,但是在简单的reasoning RL,当mismatch较小的时候(比如on-policy GRPO), token-level的TIS够用,可以防止梯度爆炸,但是训练稳定性、训练摸高效果可能由于梯度的bias会有限制。

MIS(masked IS)效果通常比TIS要更好,同样sequence-level的测试,不论在training reward还是评估分数,都能超过不用IS的原始训练。

sequence-level的MIS在更复杂、更长上下文的自回归任务上,表现的还是比token-level要好,这符合理论预期。

VeRL的rollout correction实现
| |
具体分为BypassMode以及IS/RS的实现,实现放在verl.trainer.ppo.rollout_corr_helper.py中。
apply_rollout_correction在verl.trainer.ppo.ray_trainer.py的RayPPOTrainer的fit中调用,调用场景是bypass_mode被使能,也就是不重计算old_log_prob,apply以后,实际上设置了loss_mode为rollout_correction,后续计算的时候, loss_fn会选择compute_policy_loss_with_rollout_correction(见verl.trainer.ppo.core_algos.py),在这个函数中,会on-the-fly调用compute_rollout_correction_and_rejection_mask计算IS之后的weight和modified的response mask。
而对bypass_mode关闭的模式,也就是decoupled-ppo模式,会重计算old_log_prob,相当于每个mini batch都要调用compute_rollout_correction_and_rejection_mask计算IS的weight和response make,然后添加到batch中(union),然后正常走正常的流程,比如调用compute_policy_loss_vanilla里会处理。
Slime的IS实现
可以参考合入PR,和verl类似,都实现了token/sequence/geometric mean级别的TIS、MIS等校准策略。
--use-train-infer-is: Enable training-inference importance sampling--train-infer-is-level: Aggregation level (token/sequence/geometric)--train-infer-is-mode: Processing mode (truncate/mask/clip)--train-infer-is-lower-bound/--train-infer-is-upper-bound: Weight bounds--train-infer-is-veto-threshold: Catastrophic token threshold
从理论角度解释上述的现象
前面介绍的这些研究,针对token-level, seq-level的TIS或者MIS都进行了实验,发现seq-level的效果是比token-level更好的,而且seq-level的MIS比seq-level的TIS效果更好,我们可以基于前面给出的理论分析框架和数学工具,再从本质上去理解背后的原因,做到对问题的完全理解。
回顾一下,我们通过$D_{TV}$来衡量bias,用$\chi^2$-divergence衡量variance。
我们的目标是找到一个estimator $\hat{g}$,同时能控制bias和variance。首先我们分析下常见的estimator,先定义:
$$ f(y) := \nabla_\theta \log \pi(y|x) \cdot R(y|x)$$
作为目标函数,梯度是$g = \mathbb{E}_\pi[f(y)]$。
Seq-IS
这种是最为pure的estimator:$\hat{g}_{\text{seq}} = \rho(y) \cdot f(y)$,其中$\rho(y) = \pi(y) / \mu(y)$,对每个采样进行序列级别的re-weighting,来缓解mismatch。
可以推导得到,这个estimator是unbiased:
$$ \mathbb{E}_\mu[\hat{g}_{\text{seq}}] = \mathbb{E}_\mu\left[ \frac{\pi(y)}{\mu(y)} f(y) \right] = \sum_y \mu(y) \frac{\pi(y)}{\mu(y)} f(y) = \sum_y \pi(y) f(y) = \mathbb{E}_\pi[f(y)] = g$$
所以都会优化收敛到正确的结果。而对于estimator的variance,和IS ratio的二阶矩有关
但是问题是,针对自回归的序列,二阶矩会跟随序列长度$T$呈现指数级别的增长,对于很小的比如1%的per-token差异($\bar{\chi}^2_{\min} = 0.01$),200个token的会得到variance的倍数$(1.01)^{200} \approx 7.3$。5%的mismatch会导致17292倍数的放大,这个明显是不可接受的。
当然,我们可以通过normalized的手段,去控制数值爆炸:
$$ \hat{g} = \frac{1}{N} \sum \rho_i f_i.$$$$ \hat{g}_{\text{snis}} = \frac{\sum_{i=1}^N \rho(y_i) f(y_i)}{\sum_{i=1}^N \rho(y_i)}$$
这个方式虽然能够stable,但是会导致“Sample Collapse”,也就是在高维的序列生成下,$\rho$方差会很大,可能少量的样本会主导累加和,也就是:
这样是非常不高效的,可能会抛弃掉batch中99%的数据。因此我们需要"截断"(Truncation)
Token-IS
sequence-level的IS,因为涉及到全序列的$\rho = \prod_t \rho_t$,会出现variance为指数级增长,而token-level的IS,其variance随着序列T的增长,其方差增长并非指数级的,而是多项式级的$O(T^2(1+\bar{\chi}^2))$。
token-level的estimator形式为:$ \hat{g}{\text{tok}}(y) = \sum{t=0}^{T-1} \left( \frac{\pi(y_t|x, y_{<t})}{\mu(y_t|x, y_{<t})} \right) A(s_t, y_t) \nabla_\theta \log \pi(y_t|x, y_{\text{<t}}) $
但是因为非sequence-level IS,会引入一个系统级别的bias,而且这个bias随着序列长度$T$呈二次项的增长 $O(T^2 \Delta_{\max})$。因为,这个estimator优化的,只是一个有偏的替代目标$L_μ(π)$ ,它是基于旧的状态分布$d_μ$,而不是真正的目标$J(π)$。因此,这种继承了这个偏差目标带来的$O(T^2)$偏差。
Token-TIS
PPO因为引入了clip,所以其实能较好得处理variance的问题,TIS也是类似,这个是对PPO的一种补充。朴素的思想是,如果重要性比率$\rho_t$太大了,就clip防止数值爆炸。
$ \hat{g}{\text{tl-tis}}(y) = \sum{t=0}^{T-1} \min\left( \frac{\pi(y_t|x, y_{<t})}{\mu(y_t|x, y_{<t})}, C \right) A(s_t, y_t) \nabla_\theta \log \pi(y_t|x, y_{<t}) $
通过引入对重要性比值的限制,能约束variance到多项式级别$O(T^2 C^2)$。
但是针对bias,不能修复在上文说明的$O(T^2 \Delta_{\max})$级别scale,因为bias来源于状态分布的不一致,也就是$d_\mu \neq d_\pi$,而不是来源于token级别的重要性比值权重$\rho_t$。而针对$\rho_t$的clip,是一个减少variance的技巧,而不会修正隐藏的优化目标。这种截断,反而会基于已有的$O(T^2 \Delta_{\max})$上,新增截断的bias:
$$ \text{Total Bias} = \mathbb{E}[\hat{g}_{\text{tl-tis}}] - g = \underbrace{(\mathbb{E}[\hat{g}_{\text{tl-tis}}] - \mathbb{E}[\hat{g}_{\text{tok}}])}_{B_{\text{trunc}}} + \underbrace{(\mathbb{E}[\hat{g}_{\text{tok}}] - g)}_{B_{\text{fatal}}} = B_{\text{trunc}} + O(T^2 \Delta_{\max})$$
因此,当序列长度比较长,并且off-policiness的差异比较大的场景,token-level的技巧都无法解决训练上的问题。
而且,PPO算法就好像是一个“创可贴”,虽然阻止了训练爆炸,但是模型也看不见真正的sequence-level的objective。而bias是sequence-level的问题,也必须在sequence level去解决。
Sequence-TIS
经过前面的分析,我们会发现一个dilemma:
- Seq-IS:无偏,但是variance为$O((1 + \bar{\chi}^2_{\max})^T)$级别。
- Naive/Token-IS/Token-TIS: variance是$O(T^2)$级别还行,还是bias是$O(T^2 \Delta_{\max})$级别是有偏的而且随着序列规模二次项放大。
现在分析的Seq-TIS能够解决这个dilemma,其estimator为:$$\hat{g}_{\text{sl-tis}}(y) = \min\left(\prod_{t=0}^{T-1} \frac{\pi(y_t|x, y_{
这个estimator,对variance的影响是,$\min(\rho, C)$这个ratio会被$C$限制住:
$$\mathbf{Var}(\hat{g}_{\text{sl-tis}}) \le \mathbb{E}_\mu[\|\min(\rho, C) f(y)\|^2] \le \mathbb{E}_\mu[C^2 \|f(y)\|^2]$$
也就是$\mathbf{Var} \le K^2 C^2 = O(T^2 C^2)$。这样就可以被控制了,不会无限增长。
而对于bias侧,因为引入了截断,那么就不会是无偏的估计:
$$\mathbf{Bias}(\hat{g}_{\text{sl-tis}}) = \mathbb{E}[\hat{g}_{\text{sl-tis}}] - g = \mathbb{E}_\mu[\min(\rho, C) f(y)] - \mathbb{E}_\mu[\rho f(y)]$$
这个格式
,只有当$\rho > C$的时候,才会是非零的,而是被约束为:
$$\|\mathbf{Bias}(\hat{g}_{\text{sl-tis}})\|_2 \le \frac{2 K (1 + \chi^2)}{C}$$
和token-level相比,不再是$O(T^2 \Delta_{\max})$,而是一个可以被控制的截断偏差。
因此,最终我们看到了一个基于$C$的trade-off:
- 为了减小bias,需要增大$C$。
- 为了减小variance,需要减小$C$。
所以我们可以进行目标$\text{MSE}(C) \approx \text{Bias}^2 + \text{Var}$的最优$C$求值:
$$\text{MSE}(C) \le \text{Bias}^2 + \text{Var} \le \frac{4 K^2 (1 + \chi^2)^2}{C^2} + K^2 C^2$$
可以通过计算获取到最小化MSE bound的$C$:
可以看到,最佳的截断阈值$C$,可以被表示成$\chi^2$-divergence的形式,后者是评估variance的metric,代回到最优MSE约束的表达式:
所以sequence-level的TIS,真正提供了能平衡bias和variance的estimator。
分析到此,虽然seq-level TIS看似数学上解决了bias和variance的trade-off问题,但是在真实RL场景下(推理模型CoT、长上下文agents),会出现问题打破理论的那些假设:
- 理论上,权重爆表的样本(ρ = 10 000)是“信息量巨大”的信号;实际上它往往是数值 bug、reward hacking或纯粹异常点。把它“clip”进训练,等于往模型里打毒针——直接扔掉才是正道。
- 标准的重要性采样systematically会penalizes长序列。如果把 Seq-TIS 用在 Chain-of-Thought 模型上,它很可能会先把“深度思考”打破,逼模型退化成“短平快”的肤浅回答。
所以,下面分析的Sequence-level MIS和Geo-RS才是agentic RL训练所必须的。
Sequence-MIS
针对那种非常异常的比率权重点(e.g., $\rho = 10,000$),直观的解释就是,旧的policy会以及其小的概率去生成,所以通常是OOD的样本。如果简单用Sequence-level TIS,相当于是把异常项注入到了优化过程。
所以可以进行更激进的filter:
$$ \hat{g}_{\text{seq-mis}}(y) = \mathbb{I}(\rho(y) \le C) \cdot \rho(y) \cdot f(y)$$
实际上,和Sequence-level TIS相比,MIS的侧重点不太一样。TIS侧重于最大化 information efficiency,会从所有为止获取优化信号,最好在data比较干净、mismatch比较小(e.g Online PPO)的场景使用。而MIS,侧重于最大化Safety,相当于作为置信域的filter,当mismatch比较大的时候(e.g. Offline RL)可以使用。
Geo-RS (几何平均RS)
这个技巧在现象实验的时候没有被提到,这里进行理论分析证明其能很好解决上文提到的问题2(在CoT推理模型和agents场景合适)。
举个简单的例子,$ \rho(y) = \prod_{t=1}^T \frac{\pi(y_t|y_{<t})}{\mu(y_t|y_{<t})} $
序列级别的variance因为乘积效应被指数型放大,假设新的$\pi$和$\mu$的差距不大,token平均偏差比值为1.1。如果T=10,那$\rho \approx 1.1^{10} \approx 2.6$,如果设置$C=5$, 那可以在裁剪的范围内保留,但是如果T比较大比如100,那就会被reject或者被大幅度得裁剪掉。
换句话说,标准的estimator具有内生的length bias,更偏好于从更短、更浅的回答中学习。
为了解决这个长度上的trap,可以从概率比值乘转向平均概率偏移:$\rho_{\text{geo}}(y) = \left( \prod_{t=1}^T \frac{\pi(y_t|y_{<t})}{\mu(y_t|y_{<t})} \right)^{1/T} = \rho(y)^{1/T} $
这个表征了每个token的几何平均差异,这样如果是T=10,$(1.1^{10})^{1/10} = 1.1$;如果T=100,$(1.1^{100})^{1/100} = 1.1$。可以避免长度带来的问题。
Geo-RS的estimator为:
$$\hat{g}_{\text{geo-rs}}(y) = \underbrace{\mathbb{I}\left( C_{\text{low}} \le \rho(y)^{1/T} \le C_{\text{high}} \right)}_{\text{Geometric Filter}} \cdot f(y)$$
我们用几何均值来判断“这条样本是否有效”(也就是决定 mask),但梯度到底放多大,仍按传统(裁剪后的)重要性权重来算,这样数学上才work。
总结
| Estimator | Bias (Term B) | Variance (Term C) |
|---|---|---|
| Naive/Token-TIS/PPO | $O(T^2 \Delta_{\max})$ | $O(T^2(1+\bar{\chi}^2))$ |
| Seq-IS | 0 | $O((1 + \bar{\chi}^2_{\max})^T)$ |
| Seq-TIS | $O(T(1+\chi^2)/C)$ | $O(T^2 C^2)$ |
| Estimator | Mechanism | The “Why” |
|---|---|---|
| Token-IS (PPO) | Breaks chain rule. | Legacy. Stable but biased. $O(T^2\Delta_{\max})$ |
| Seq-TIS | Clips total weight. | Math Optimum. Best bias/variance trade-off for clean data. |
| Seq-MIS | Rejects total weight. | Safety. Filters the “Toxic Tail” (garbage data). |
| Geo-RS | Rejects on per-token drift. | Stability. Solves the Length Bias to enable deep thinking. |
Routing Replay
https://arxiv.org/html/2510.11370v1
https://arxiv.org/html/2510.23027v1 RSPO routing fluctuations
Rollout Routing Replay 主要解决在专家混合(MoE)大模型中,因其路由机制在训练和推理阶段的行为不一致,导致训练和推理的 logprob产生比较大的差异进而引起强化学习(RL)训练不稳定甚至崩溃的问题。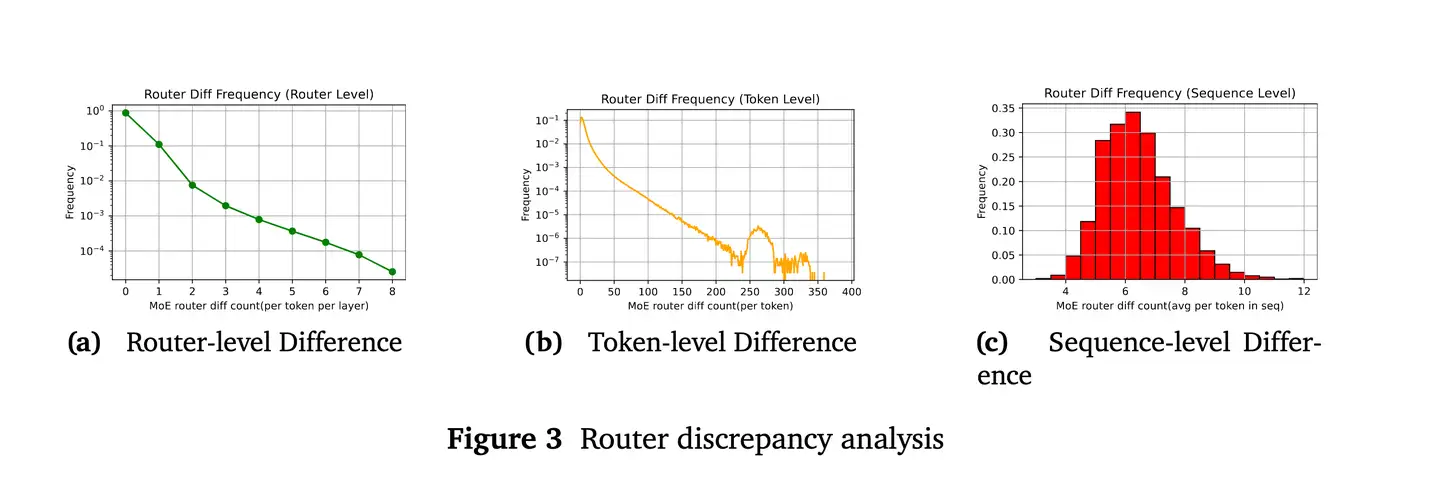
Rollout Routing Replay 会在模型进行推理时(Rollout 阶段),记录下每个 token 的 router 分布,然后在后续的训练过程中使用这些 router 分布进行计算。通过这种方式,强制训练过程模仿并对齐推理时的 router 行为,从而弥合两者之间的差异。
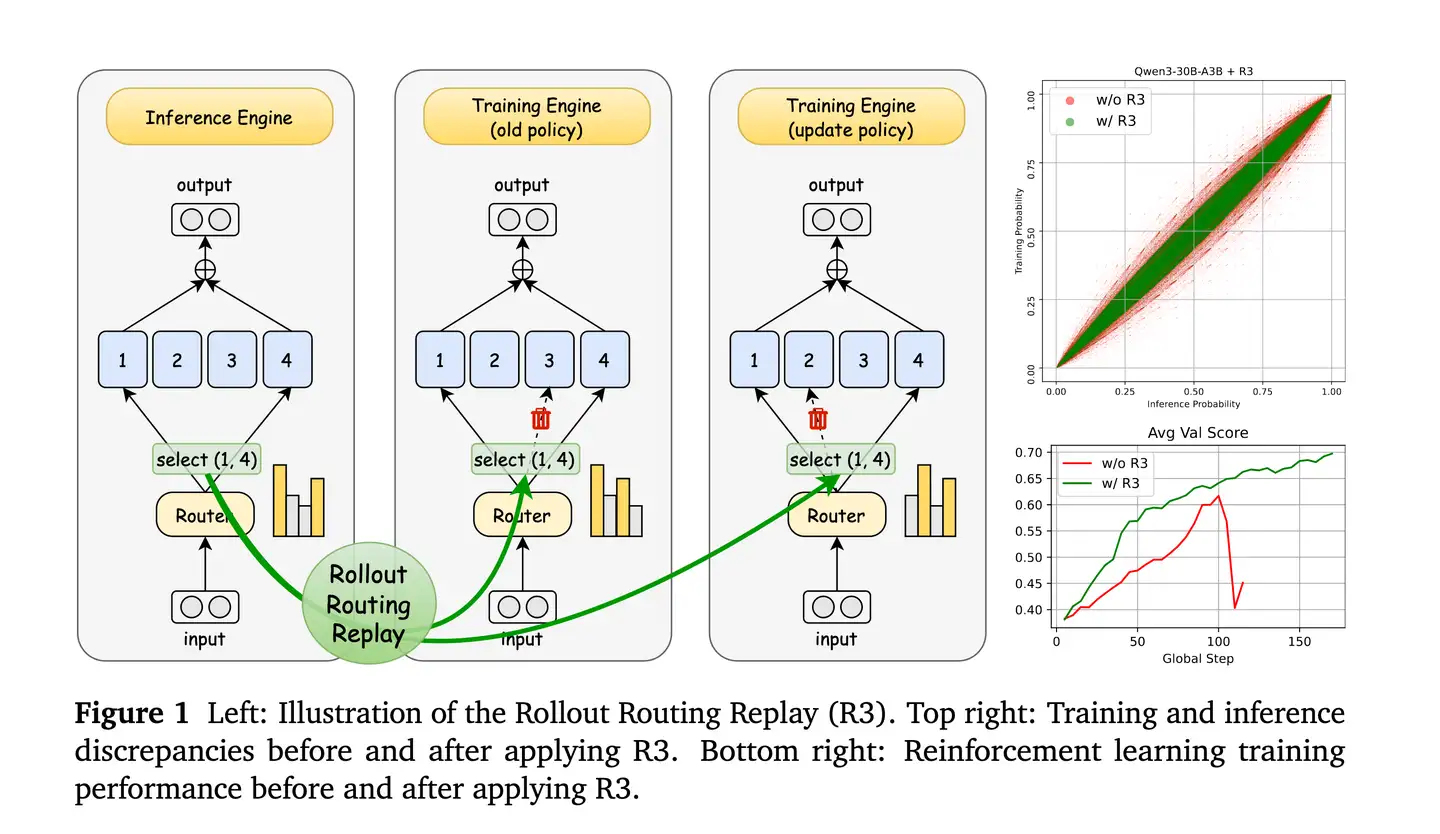
需要注意的是, GSPO论文中提到的Routing Replay, 是训练侧old和target策略之间,如果进行token-level的重要性采样,可能导致专家激活模式在新旧策略之间有差异,这种路由波动可能破坏训练稳定性,GSPO因为引入了seq-level的重要性采样,对单个token的专家波动不敏感,可以不需要routing replay(而GRPO不引入routing replay容易训崩)。而上面讨论的routing replay,主要还是解决训推不一致导致的路由波动带来的问题。
值得注意的其他研究
BF16切换为FP16
有一篇更新的(2025/10/30)的来自Sea AI Lab的文章Defeating the Training-Inference Mismatch via FP16 提出了一个更简单的statement:我们不需要上面这些复杂的算法修正,只需要把精度从BF16切回FP16,不一致带来的问题就会解决。

研究认为,虽然FP16和BF16都使用总计16位,单比特分布不一样,尾数项和指数项的差异,导致FP16的精度为BF16的8倍。但带来的trade-off就是FP16能表征的数值范围就小的多,容易会overflow,可能需要额外的技巧比如loss scaling(反向之前把计算得到的loss乘大的缩放因子,反向时用放大了的loss计算梯度,落入fp16可表征的范围,利用梯度更新权重之前把梯度再还原回去)等稳定性技术进行缓解。
文章作者认为,在RL后训练的阶段,模型权重基本已经经过了pre-training,数值分布相对稳定,配合loss scalling等技巧fp16可以保证训练稳定。实际上这个是一个非常重要的场景预设,也是这个研究的出发点。因为BF16格式在LLM训练中,被广泛使用的原因,就是其既能够表征FP32的数值范围(指数位都是8),从而在预训练的时候,甚至不需要loss scaling这种增加复杂度的工程实现,也可能做到训练的稳定性,而且显存占用和全精度比也省一半。这种流行,是建立在pre-training对精度问题的“宽容度”比较高这个前提上的:
- 在pre-training阶段,模型在海量的数据上学习通用的统计规律,pre-training过程有很强的鲁棒性,对数值噪声不敏感。
和pre-training阶段只关心“预测的next token是否准确”相对的,RL post-training更关注的是策略的更新幅度,例如PPO就依赖新旧策略的的ratio,通过限制ratio不要偏离1太远来保证训练稳定,这对训练时的精度需求就会更为严苛,如果由于精度表征问题,导致本来有差异的新旧策略,被截断成了ratio=1,那么策略就不更新了。而且针对KL散度约束这种设计到log计算的,精度差异带来的影响会在对数域被放大,那KL算不准,reward model给出奖励信号可能导致模型迅速过拟合到某个错误的pattern上,或者训练非常不稳定。
因此这里的takeaway简单来说,就是在RL场景下,梯度的数值范围通常没有pre-training方差那么大,对梯度的精度要求更高,所谓为了获得比bf16高8倍的精度表征,用fp16 + loss scaling增加的工程成本是值得的。
